人工智能入門(下篇)

這篇是這個系列的完結篇,為何兩篇就完?其實我想讓大家知道的是它怎樣運作,它是怎樣去學習,那就可以判定怎樣應用它到你的項目上,上一篇是作一個基本認識,而這篇就是集中在應用層面上的解說。 雖我的標題有點取巧(因’人工智能’這個 keywords 看似對 SEO 有幫助 XD),其實我說的都只是人工智能的其中一類(神經網絡),它是人工智能的其中一大流派,師承 Connectionism,近年的火熱的 Deep Learning 更是把這派發揚光大,令科網大老們都加入這一流,那我們當然是選一個大的幫派去學藝。 筆者這些年在研究的是自然語言處理 NLP(Natural Language Processing),因當時覺得要做人工智能最少要先令電腦明白我們的語言,早幾年前神經網絡還未非常流行(雖神經網絡早在1943年已問世,直到最近幾年才有突破),那時用的都是一些 Statistical 模型,如:HMM(Hidden Markov model)、CRF(Conditional random field) 等,這些模型在針對性的任務上效果算不錯,但是人類的語言是不斷變化,只用過去的數據去作模型,處理新的資料準確性是一定會大打折扣,但 Deep Learning 出現令我對 NLP 更有希望,所以我想用 NLP 這個例子去解話一下,我怎樣用 Machine Learning 去解決問題。
神經網絡的品種
先認識一下它們的種類,就像我們的神經系統,進化令我們發展出針對不同需要的神經結構,如眼球與大腦之間的神經、聽覺神經、反應神經等,它們的神經元本身可能大同小異,但是結構上是獨自發展來應付它們的天職,但它們可塑性高,神經受損了可透過訓練其他健康的神經去彌補。 我們試從它們解決問題的途徑大致分三大類:
空間性 Spatial:「前饋網絡 Feedforward Neural Network (FNN)」
最常用的網絡,衍生的網絡架構非常之多,但大同少異,它的強項都是空間性任務,即是分類。常用的有:
Multiple Layers Perceptron (MLP)
Convolutional Neural Network (CNN)
Restricted Boltzmann Machine (RBM)
Stacked Demonising Autoencoder (SdA)
時間性 Temporal:「遞歸神經網絡 Recurrent Neural Network (RNN)」
它基本上是和 FNN 一樣的,分別是它把前一次的輸出值作為下一次的輸入值,所以每一次的輸出都受上一次的影響,適合作時間性的任務如 Prediction 預測。 常用的有:
Gated Recurrent Unit (GRU)
Long Short Term Memory
聚類 Clustering:「聯想記憶 Associative Memories」
就如其名都是和記憶有關的任務,它可以參考你給它的輸入值從訓練後的記憶中找出近似的值。
Self-Organising Maps (SOM)
Bidirectional associative memory (BAM)
它們是可以互相組合成其他的網絡如 Hopfield Network 是種 RNN + Associative Memory 可作時間性的記憶判定、而 Echo State Network / Liquid State Machine 的 cell 是一堆隨機 RNN + FNN 可以應付 Spatio-Temporal Pattern。 新的網絡架構可能每天都有人在研發中,我只列出我所認識的其中幾種,有些蕓花一現很快被更好的取代了。
那種網絡適合我?
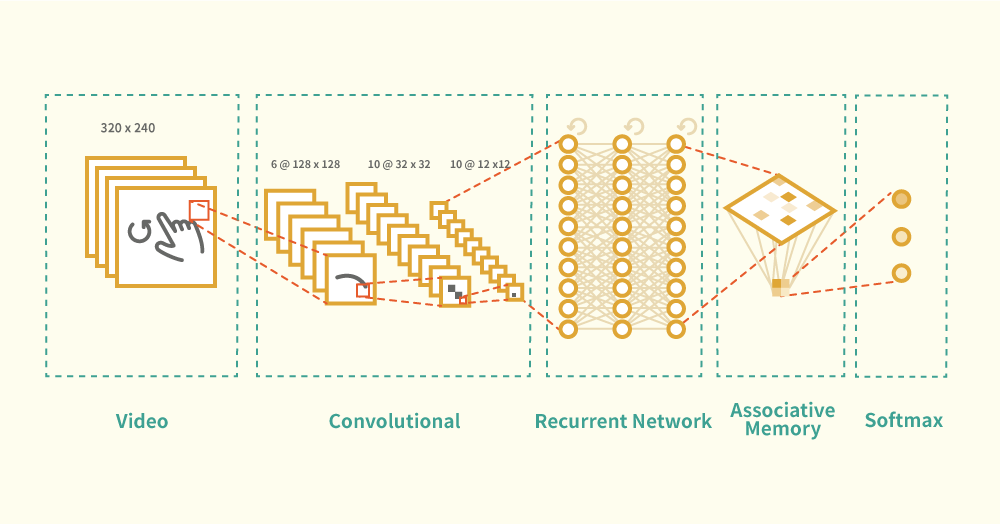
我試用一個可用盡三類網絡的例子去解釋一下,好!我們來做一個思想實驗 Thought Experiment,假設我的項目是手勢辨識(Gesture Classification)
第一件事是要由視頻中找出那部分是用戶的手,先把視頻分降成一連串畫面序列,再在每一個畫面中去找,這是一個空間中作分類的工作,就如面容辨認一樣,那 FNN 可大派用場,在解像 320 x 240 的視頻畫面中每一個 frame 有共 76800 個 pixels,把這堆 pixels 作為輸入值實在是太大了,那需要為輸入值減減磅,Deep Learning 的 CNN 和 SdA 都是非監督學習 Unsupervised Learning 方法去作降維 Dimensionality Reduction 的前饋網路,假設選用 3 層 CNN,把維度降低到 12 x 12 作為第一組的空間分類工作,得出空間性的特徵。
那下一步是時間性的分類,手勢動作可能要一至三秒去完成,每一格的畫面都由前一組 CNN 的輸出值作為 RNN 的輸入值,以一格一次輸入到 RNN,假設選用 2 層 GRU, 隱藏單元數 Hidden Unit 數量越多它對過去的畫面記憶越敏感,假設每層有 256 個單元足夠表達前 3 秒的所有畫面特徵,那它的輸出就是時間性的特徵了。
如人類的聯想記憶是看見有熟識的行為出現時就跳出一個過去的記憶,它是非常重要,可大大減少我們腦袋的工作量,我們的視覺神經都不時為我們補完一些看不見的影像從而減少盲點。每一次手勢動作可能位置都有輕微不同,聯想記憶會模糊地在記憶中找出最相似的組合位置,假設用 SOM 把 RNN 的輸出值作為輸入,SOM 的輸出是一個組合性 2 維特徵,就像 x、y 坐標,它會把相似的輸入聚在同一個組合中。
最後加 Softmax 或 Argmax 作輸出層,它是把穩藏層的內部特徵輸出成我們可以解讀的 Local Representation,假設是要認出三種手勢,那輸出是:
Softmax:
[1, 0, 0] # 表示是第一個手勢
[0, 1, 0] # 表示是第二個手勢
[0, 0, 1] # 表示是第三個手勢
就這樣這個網絡組合就完成了,這例子中的 Parameters 都是假設的,實際上是要透過訓練時去 Fine Tune,不用等訓練到最後,只要比較特定 Iterations 中的 Losses 就可大約知道效率在那個 Parameters 組合中最高。
先把你要解決的問題拆分成一個個小的問題,再依照我的分類方法你可以從這三類網絡中去想想你的項目是那一種能解決。
但是我們怎知道該選那一個作 FNN 又該選那一個作 RNN ?我的做法是去找近似項目的 Paper,他們多數會比較不同的做法,和總結最好的方法,再到 Github 找有沒有人把 Paper 的方法 Implement 出來,因筆者完全看不同 Paper 中的代數公式,沒有能力去 Implement,那只好靠 Github 的神人了。 PS:其實這例子可以不用加聯想記憶在最後都可能有差不多的效果。
怎樣開始動手試?
比較建議 Clone 別人的玩玩,改動一下,看看它的變化,很多 Repo 的 Parameters 未必是最好的,很多開發者都很歡迎你去試。
先選一個 Framework,看一看它支援的網絡中,有沒有你需要的。比較多人選用的 Theano、Tensorflow、Torch 都是 Low-Level 的 Framework,Learning Curve 比較高;High-Level 的有 Keras、Blocks 和 Lasagne 等⋯
準備訓練用的 Dataset,以之前的例子,你需要一定數量的視頻,和為每一個視頻標註好它是那一個手勢。
硬件上的要求視乎 Dataset 數量,和網絡複雜程度,用一台 Macbook Pro 都可以玩了,但看你想等多久了。
NLP(Natural Language Processing)
過去的 NLP 任務都著重於標註任務,這些任務都是把我們的語言標註起來令電腦明白當中的關係,好讓電腦用數學方法去分析,如你想知道兩段句子意思上的相似度時,只看它們每一隻單字是完全找不著關連,NLP 可讓它知道的是:
分詞 Tokenizer - 句子經過分詞得出詞 Word 和 片語 Phrase
詞性標註 Part-of-speech - 令它可以知道那些詞是動詞,那些是名詞
命名實體 Named-entity-recognition - 令它可知那個詞是指人名,那個字是指地方名
依存句法 Dependency Parser - 令它知道 Grammer 是否相似
但是人類言語中存在太多模糊 Ambiguity,到現時以上任何任務都未有程式做到100%準確度,人類世界對電腦來說太複雜了⋯⋯ 但近年 Google 推出了 word2vec,全寫是 Word to Vector,它的出現令 NLP 起了很大變化,它給每一個詞都影射到一個高維度的空間坐標,有了坐標就可從距離得知詞與詞的關係,把語言變成了數學問題。
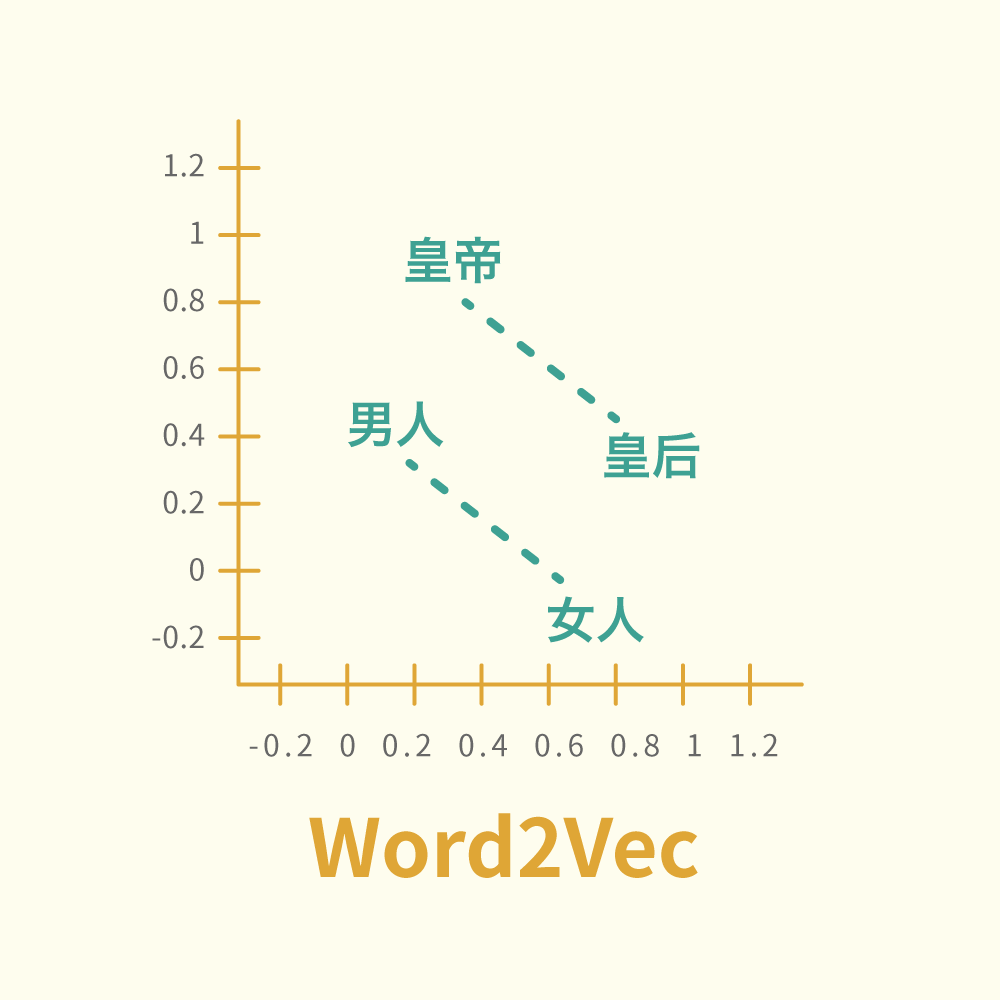
來看一個簡單的數學例子:
(皇帝 - 男人) + 女人 = 皇后
這條數式是非常地簡單及有效率,但它是怎樣做到?現在有三種方法去訓練出 word2vec,慨括而言是給網絡一個或多個詞要它去估下一個可能出現的詞,從中得知詞之間的關係,這個不在這裡講太多。 當這世界所有東西都化成這樣的數學特徵 Representation,解決問題的方法就變得很簡單,前題是如何訓練出足夠代表性的特徵,似乎又是落在訓練方法的創新性上。
總結
神經網絡中每一個神經元其實都是一個特徵,但它代表什麼,我們不用去深究,因現實世界都是一樣,不是所有東西都可解釋,也不是所有東西都只得一個解釋,Deep Learning 就是用不同的學習方法去令網絡中的每一個單元學得最好的特徵,當問題複雜度越高,Supervised Learning 就變得很費時失事,未來的 Machine Learning 都是會向開發更創新的結構和學習方法作方向, 文章中最後一節 NLP 是想鋪路下一篇的文章,RAM (Reasoning, Attention, Memory) 是邏輯對答機的三個重要元素,2015年間 Machine Learning 研究裡其中一個重要成果,這會是做出能用人類語言來和我們溝通的人工智能重大一步。
comments powered by Disqus