人工智能入門(上篇)

簡介
這個系列主要是為一些有興趣人工智能,和想了解這個技術如何可應用到他們 Startup 的人而設,主要著重於應用層面。
業界中多數用 Machine Learning 這個詞,那跟 AI 有什麼分別呢?其實 Machine Learning 是 AI(Artificial Intelligence) 的其中一種,由機器自己學習去解決問題,現今 AI 的定義已變了不少,為解決一些特定任務如人面辨識、Spam filter、無人駕駛等都可說是 AI,那電影中會消滅人類的那種現可以叫作 Super Intelligence 或 Artificial general intelligence (AGI) 都是接近或超越人類智慧等級的機器。
這兩年是人工智能競賽最激烈的時代,有兩個重要因素,第一是幾個龍頭公司都 open source了自己的 framework 為了搶得業界標準地位,大家都知 open source 的世界多人用的 framework 才會多人 contribute, 這一點是非常重要,因現在多人研究這個範疇,相關的 paper 數量大增,新的 deep learning architecture 越來越多, open source 了的 framework 才有望成為研究員的主要工具,去為 framework 加入更多 algorithm;另一點是硬件的配合,GPU 成了催化劑把運算速度大大提高,Nvidia 看準這塊肥肉推出了針對 Machine Learning 的怪獸級顯示卡, 還有 Amazon 的 GPU Cluster 也居功不少。
Neural Network(神經網絡)
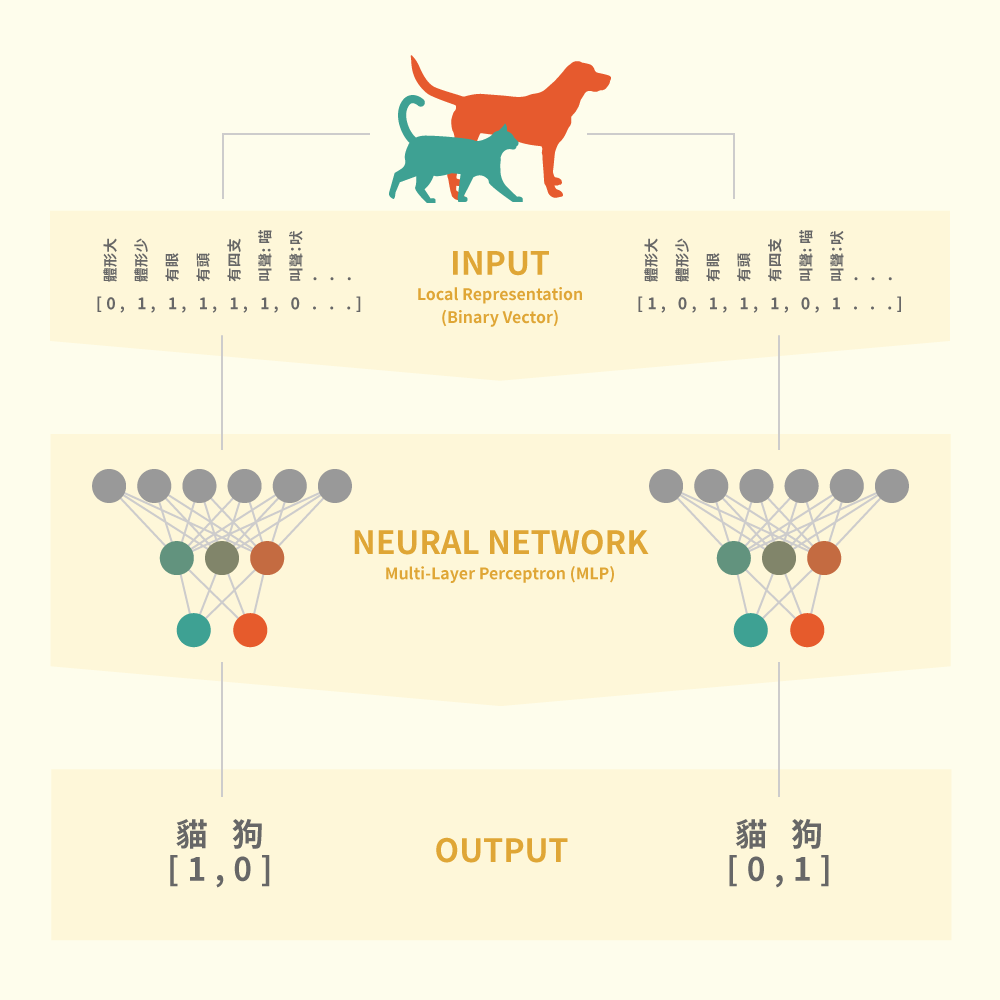
圖一
神經網絡是 Machine Learning 中的主流方法,它的種類非常之多,我先講講最基本的 Multiple Layer Perceptro(MLP),我想用一個很簡淺有趣的方法來介紹它。
特徵 Feature 假設你的項目有需要作分類(Classification)或預測(Prediction)的任務時它都可以大派用場,那它是如何做到分類或預測的任務? 簡單來說它是仿效我們腦袋運作的方法去解決問題,你可想想你是如何分辨眼前的是一頭貓喵而不是狗? 就是由特徵去分類,比如體形大小、嘴面、聲音等… 那有了特徵下一步是怎樣做分類?
前饋(Feed Forward)
圖一中的三層神經網絡中每一點代表一個 Perceptron,每個 Perceptron 都有它們的權重數值(Weight),在初始設定時每粒 Perceptron 的權重都是隨機設定,上層每一粒 Perceptron 都會連到下一層的 Perceptrons,當把特徵由輸入層推至到輸出層的過程就是前饋。
後饋(Back Propagation)
學習的過程是以不斷的迭代(Iteration)來達到錯誤最小化 ,每一次迭代時把輸出的結果比較目標資料,把差距作為成本(Cost),有了成本後再利用後饋算法把每層的 Perceptrons 權值作更新。
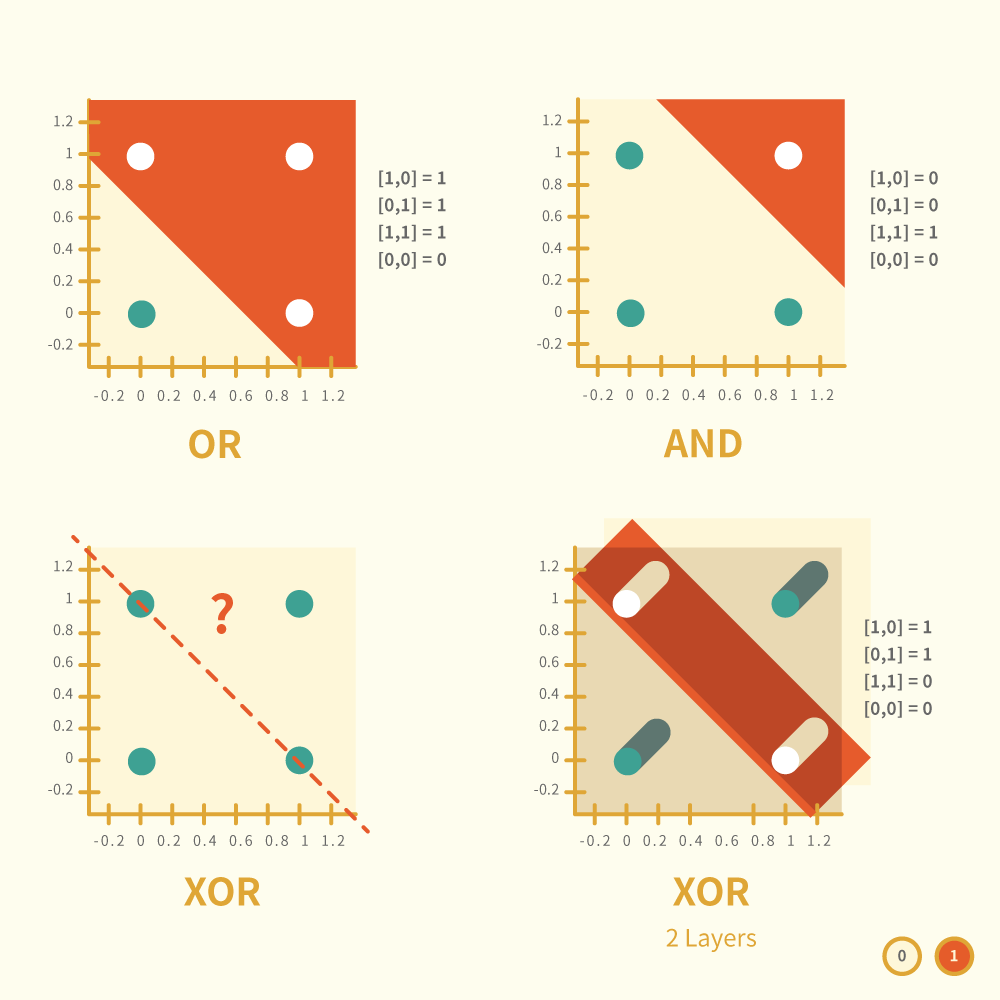
圖二
線性代數(Linear Algebra)
要了解神經網絡就一定要明白線性代數,電腦的運算方式不外乎加減乘除,要它明白我的世界就必需把東西化成數值,一組以上的數值形成多維空間,換句話說構成空間要最少有二個或以上的數值,二維的空間就有兩個數值作參考,比如坐標 [x, y] ,如果在空間中加上一條線就會畫分成兩邊,坐標落在線的那邊就代表已被分到那一類,這就是用線性作分類的方法了。 在神經網絡中每一層都是一個空間,那為什麼要加多另一個空間呢?這時候要引用經典例子 XOR(圖二)來解釋了: 圖二中的二維空間可容易解決 OR 或 AND 的數學邏輯,但對於 XOR 就無能為力了(圖二左下)。 當兩個空間疊加時它們的線會形成面(圖二右下),這樣就可以畫分出 XOR 了。
Deep Learning
Deep Learning 的網絡種類很多,把字拆可解作用特別的學習(Learning)方法達至把網絡層數加深(Deep),而層數增加後使神經網絡可解決更復雜的問題,就如圖二的 XOR。 在圖一的例子中輸入層和輸出層都是我們預先設計好的,這種叫監督學習(Supervised Learning),如果把輸入層換作是圖像的點陣(pixels) 加幾層 Deep Learning 的網絡就可以免去我們選擇特徵的過程達到半監督學習(Semi-supervised Learning)的效果,有了 Deep Learning 免去了大量人手選料, 在未有 Deep Learning 前 Network 的層數不可太多,因把資料從輸入層推入到 Hidden Layer 後,我們無法得知投射後的表徵每一個數值的意義,所以有人稱它是個黑盒(Blackbox)裡面的東西是無法觀察,另外層數越多越無法判斷它們的學習效率,使神經網絡學習過程中很易走向 Overfitting 即是它處理你給它準備好的學習用資料(Dataset)它可以努力學習作出準確推算,但遇上 Dataset 以外的資料輸出結果卻強差人意。
應用
假如你現在就想動手做,在 Github 上有不少 project 可以參考,不論你打算用那一個 framework 都好,你都要知道那個作參考 project 的目的,因為上面大多都是為研究或測試目的,十居其九都是一些跟 paper implement 出來的 project 和 benchmark 的 project,這和應用層面是兩碼子的事,那應該怎樣去把 Deep Learning 項目整合到你的項目呢? 基本上神經網絡訓練好後我們需要的只是它們的權重數值(Weights) 或一些 parameters,那之後不論在手機上或 server 上都是用這推權重值去解決問題。 訓練方法會因應用的目的分成 Offline 或是 Online Learning,Offline 即是你灌一堆資料讓神經網絡埋頭苦幹幾千次迭代後把成果作成應用,但你想更新它時,你只可把新資料再灌它一次了;Online 是指網絡會在應用中去學習,但未必會更新整個網絡,可能只更新特定某幾層的權重。
預告
下一編的內容是介紹不同類型的 Deep Learning 神經網絡及 Machine Learning 如何作自然語言處理 NLP(Natural Language Processing)和怎樣讓電腦明白我們的語言。
comments powered by Disqus